In this blog, I’ll provide a brief rundown of all the concepts used in deep neural networks.
To be covered:
1. What is Deep Learning?
2. Working of Deep Neural Network with an example.
3. Activation Functions
- Why activation functions are required?
- Different activation functions
4. Loss/ Cost Functions
- Use of loss/ cost function
- Different loss functions and its use case
- Which loss function to use?
5. Optimizers
- Why optimizers are required?
- Gradient Descent (GD) and its variants
- GD optimization methods and which optimizer to use?
6. Conclusion
Researchers tried to mimic the working of the human brain and replicated it into the machine making machines capable of thinking and solving complex problems. Deep Learning (DL) is a subset of Machine Learning (ML) that allows us to train a model using a set of inputs and then predict output based.
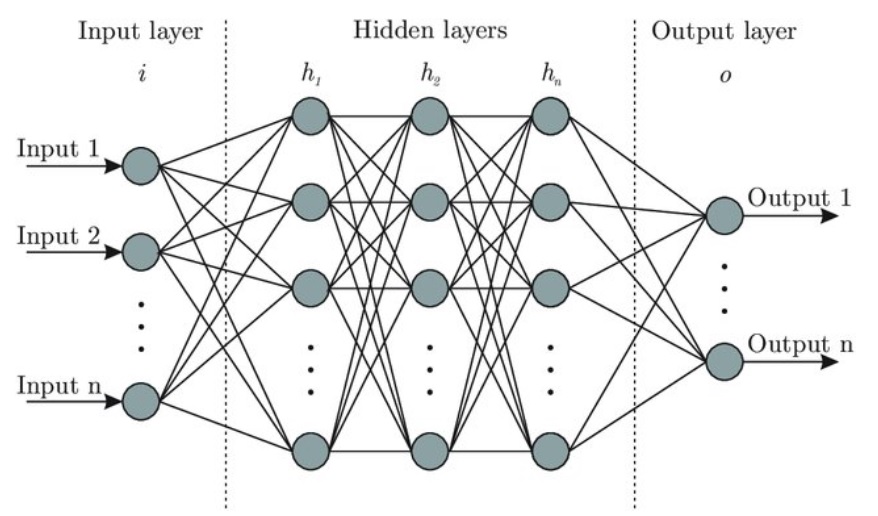
Like the human brain, the model consists of a set of neurons that can be grouped into 3 layers:
It receives input and passes it to hidden layers.
There can be 1 or more hidden layers in Deep Neural Network (DNN). “Deep” in DL refers to having more than 1 layer. All computations are done by hidden layers.
This layer receives input from the last hidden layer and gives the output.
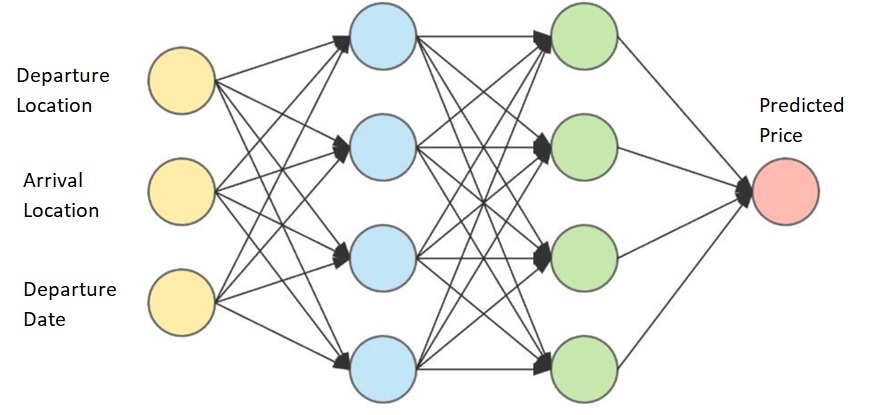
We will see how DNN works with the help of the train price prediction problem.
For simplicity, we have taken 3 inputs, namely, Departure Station, Arrival Station, Departure Date.
In this case, the input layer will have 3 neurons, one for each input.
The first hidden layer will receive input from the input layer and will start performing mathematical computations followed by other hidden layers. The number of hidden layers and number of neurons in each hidden layer is hyperparameters that are challenging task to decide.
The output layer will give the predicted price value. There can be more than 1 neuron in the output layer. In our case, we have only 1 neuron as output is a single value.
Now, how the price prediction is made by hidden layers? How computation is done inside hidden layers?
This will be explained with help of activation function, loss function, and optimizers.
Each neuron has an activation function that performs computation. Different layers can have different activation functions but neurons belonging to one layer have the same activation function.
In DNN, a weighted sum of input is calculated based on weights and inputs provided. Then, the activation function comes into the picture that works on weighted sum and converts it into output.
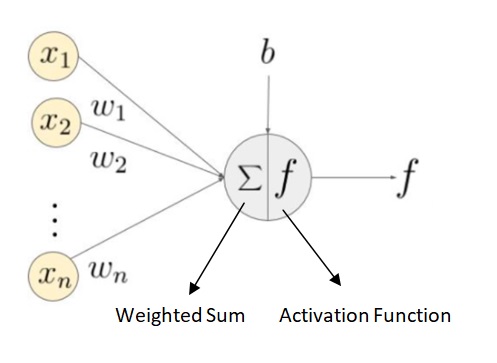
Why activation functions are required?
Activation functions help model learn complex relationship that exists within the dataset. If we do not use the activation function in neurons and give weighted sum as output, in that case, computations will be difficult as there is no specific range for weighted sum. So, the activation function helps to keep output in a particular range. Secondly, the non-linear activation function is always preferred as it adds non-linearity to the dataset which otherwise would form a simple linear regression model incapable of taking the benefit of hidden layers.
Keeping it short and not going into computational details, describing use case scenarios of activation functions.
a. Sigmoid
*In case weights update are very small, there will be no or slow convergence leading to vanishing gradient problem.
b. Softmax
c. tanh
d. relu
*In case weights update are large, there will be overshooting of minima and hence no convergence leading to exploding gradient problem.
There exists some varients of relu function such as leaky relu, elu, selu. Similarly, variants of sigmoid are softplus, softsign etc.
Which activation function to use?
The relu function or its varients is mostly used for hidden layers and sigmoid/ softmax function is mostly used for final layer for binary/ multi-class classification problems.
4. Loss/ Cost Function
To train the model, we give input (departure location, arrival location and, departure date in case of train price prediction) to the network and let it predict the output making use of activation function. Then, we compare predicted output with the actual output and compute the error between two values. This error between two values is computed using loss/ cost function. The same process is repeated for entire training dataset and we get the average loss/error.
Now, the objective is to minimize this loss to make the model accurate.
Use of loss/ cost function
There exist weights between each connection of 2 neurons. Initially, weights are randomly initialized and the motive is to update these weights with every iteration to get the minimum value of the loss/ cost function. We can change the weights randomly but that is not efficient method.
Here comes the role of optimizers which updates weights automatically.
Different loss functions and their use case
Loss function is chosen based on the problem.
a. Regression Problem
Mean squared error (MSE) is used where real value quantity is to be predicted.
MSE in case of train price prediction as price predicted is real value quantity.
b. Binary/ Multi-class Classification Problem
Cross-entropy is used.
c. Maximum- Margin Classification
Hinge loss is used.
5. Optimizers
Once loss for one iteration is computed, optimizer is used to update weights.
Why optimizers are required?
Instead of changing weights manually, optimizers can update weights automatically in small increments and helps to find the minimum value of the loss/ cost function. Magic of DL!!
Finding minimum value of cost function requires iterating through dataset many times and thus require large computational power.
Common technique used to update these weights is gradient descent.
Gradient Descent (GD) and its variants
It is used to find minimum value of loss function by updating weights.
There are 3 variants of GD:
a) Batch/ Vanila Gradient
b) Stochastic Gradient Descent (SGD)
c) Mini-batch Gradient Descent
GD optimization methods and which optimizer to use?
To overcome challenges in GD, some optimization methods are used by AI community. Further, less efforts are required in hyperparameter tuning.
a) Adagrad
b) Adadelta
c) RMSprop
d) Adam
To sum up, DNN takes the input which is worked upon by activation function to make computation and learn complex relationship within dataset. Then, loss is computed for entire dataset based on actual and predicted values. Finally, to minimize the loss and making the predicted values close to actual, weights are updated using optimizers. This process continues till model converges with the motive of getting minimum loss value.
– DNN imitates human brain to solve complex problems.
– Three layers, namely, input, hidden and output layer exist in DNN.
– Each neuron has activation function that helps learn relation in data.
– Relu is generally used in hidden layers and sigmoid/ softmax for final layer.
– Cost/ loss function is computed by iterating through dataset.
– MSE and cross-entropy are most common loss function used in regression and binary/ multi-class classification problem respectively.
– Optimizer is used to update weights in neural network.
– Adam is the best overall choice and has faster convergence compared to GD.
Thanks for reading this article on Deep learning. Please let me know about your experience of reading this article in comment section.
Follow me on LinkedIn
The media shown in this article on Deep Learning are not owned by Analytics Vidhya and is used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,







