The rapid evolution of generative AI models, exemplified by OpenAI’s ChatGPT, has significantly advanced natural language processing and understanding. At the heart of these advancements lies the meticulous fine-tuning of machine learning models on diverse and extensive training data. This process ensures that the models can handle a wide array of queries and generate coherent, contextually relevant responses. However, to achieve peak performance in specialized fields, domain-specific fine-tuning using targeted datasets becomes essential. Incorporating vector databases and techniques like RAG (Retrieval-Augmented Generation) further enhances this capability, enabling efficient retrieval and organization of vast amounts of information
Open source tools and resources play a pivotal role in this ecosystem, fostering innovation and accessibility in the realm of generative AI. This article delves into these critical aspects, exploring how they collectively elevate the efficacy and applicability of modern machine learning systems.

This article was published as a part of the Data Science Blogathon.
Retrieval-Augmented Generation, or RAG, represents a cutting-edge approach to artificial intelligence (AI) and natural language processing (NLP). At its core, RAG LLM is an innovative framework that combines the strengths of retrieval-based and generative models, revolutionizing how AI systems understand and generate human-like text.
The development of RAG is a direct response to the limitations of Large Language Models (LLMs) like GPT. While LLMs have shown impressive text generation capabilities, they often struggle to provide contextually relevant responses, hindering their utility in practical applications. RAG LLM aims to bridge this gap by offering a solution that excels in understanding user intent and delivering meaningful and context-aware replies.
RAG is fundamentally a hybrid model that seamlessly integrates two critical components. Retrieval-based methods involve accessing and extracting information from external knowledge sources such as databases, articles, or websites.
On the other hand, generative models excel in generating coherent and contextually relevant text. What distinguishes RAG is its ability to harmonize these two components, creating a symbiotic relationship that allows it to comprehend user queries deeply and produce responses that are not just accurate but also contextually rich.
To grasp the essence of RAG LLM, it’s essential to deconstruct its operational mechanics. RAG operates through a series of well-defined steps:
Central to understanding RAG is appreciating the role of Large Language Models (LLMs) in AI systems. LLMs like GPT are the backbone of many NLP applications, including chatbots and virtual assistants. They excel in processing user input and generating text, but their accuracy and contextual awareness are paramount for successful interactions. RAG strives to enhance these essential aspects through its integration of retrieval and generation.
RAG’s distinguishing feature is its ability to integrate external knowledge sources seamlessly. By drawing from vast information repositories, RAG augments its understanding, enabling it to provide well-informed and contextually nuanced responses. Incorporating external knowledge elevates the quality of interactions and ensures that users receive relevant and accurate information.
Ultimately, the hallmark of RAG is its ability to generate contextual responses. Moreover, it considers the broader context of user queries, leverages external knowledge, and produces responses demonstrating a deep understanding of the user’s needs. Consequently, these context-aware responses are a significant advancement, as they facilitate more natural and human-like interactions, making AI systems powered by RAG highly effective in various domains.
Retrieval Augmented Generation (RAG) is a transformative concept in AI and NLP. Additionally, by harmonizing retrieval and generation components, RAG addresses the limitations of existing language models and paves the way for more intelligent and context-aware AI interactions. Furthermore, its ability to seamlessly integrate external knowledge sources and generate responses that align with user intent positions RAG as a game-changer in developing AI systems that can truly understand and communicate with users in a human-like manner.
In this section, we delve into the pivotal role of external data sources within the Retrieval Augmented Generation (RAG) framework. We explore the diverse range of data sources that can be harnessed to empower RAG-driven models.

APIs (Application Programming Interfaces) and real-time databases are dynamic sources that provide up-to-the-minute information to RAG-driven models. Moreover, they allow models to access the latest data as it becomes available.
Document repositories serve as valuable knowledge stores, offering structured and unstructured information. Additionally, they are fundamental in expanding the knowledge base that RAG models can draw upon.
Web scraping is a method for extracting information from web pages. Furthermore, it enables RAG LLM models to access dynamic web content, thereby making it a crucial source for real-time data retrieval.
Databases provide structured data that can be queried and extracted. Additionally, RAG models can utilize databases to retrieve specific information, thereby enhancing the accuracy of their responses.
Let us now talk about benefits of Retrieval Augmented Generation.
RAG addresses the information capacity limitation of traditional Language Models (LLMs). Traditional LLMs have a limited memory called “Parametric memory.” RAG introduces a “Non-Parametric memory” by tapping into external knowledge sources. This significantly expands the knowledge base of LLMs, enabling them to provide more comprehensive and accurate responses.
RAG enhances the contextual understanding of LLMs by retrieving and integrating relevant contextual documents. This empowers the model to generate responses that align seamlessly with the specific context of the user’s input, resulting in accurate and contextually appropriate outputs.
A standout advantage of RAG is its ability to accommodate real-time updates and fresh sources without extensive model retraining. Moreover, this keeps the external knowledge base current and ensures that LLM-generated responses are always based on the latest and most relevant information.
RAG-equipped models can provide sources for their responses, thereby enhancing transparency and credibility. Moreover, users can access the sources that inform the LLM’s responses, promoting transparency and trust in AI-generated content.
Studies have shown that RAG models exhibit fewer hallucinations and higher response accuracy. They are also less likely to leak sensitive information. Reduced hallucinations and increased accuracy make RAG models more reliable in generating content.
These benefits collectively make Retrieval Augmented Generation (RAG) a transformative framework in Natural Language Processing. Consequently, it overcomes the limitations of traditional language models and enhances the capabilities of AI-powered applications.
RAG offers a spectrum of approaches for the retrieval mechanism, catering to various needs and scenarios:
These diverse approaches empower RAG to adapt to various use cases and retrieval scenarios, allowing for tailored solutions that maximize AI-generated responses’ relevance, accuracy, and efficiency.
RAG introduces ethical considerations that demand careful attention:
RAG finds versatile applications across various domains, enhancing AI capabilities in different contexts:
These applications highlight how RAG’s integration of external knowledge sources empowers AI systems to excel in various domains, providing context-aware, accurate, and valuable insights and responses.
The evolution of Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs) is poised for exciting developments:
The following diagrams illustrate the LangChain workflow for RAG.
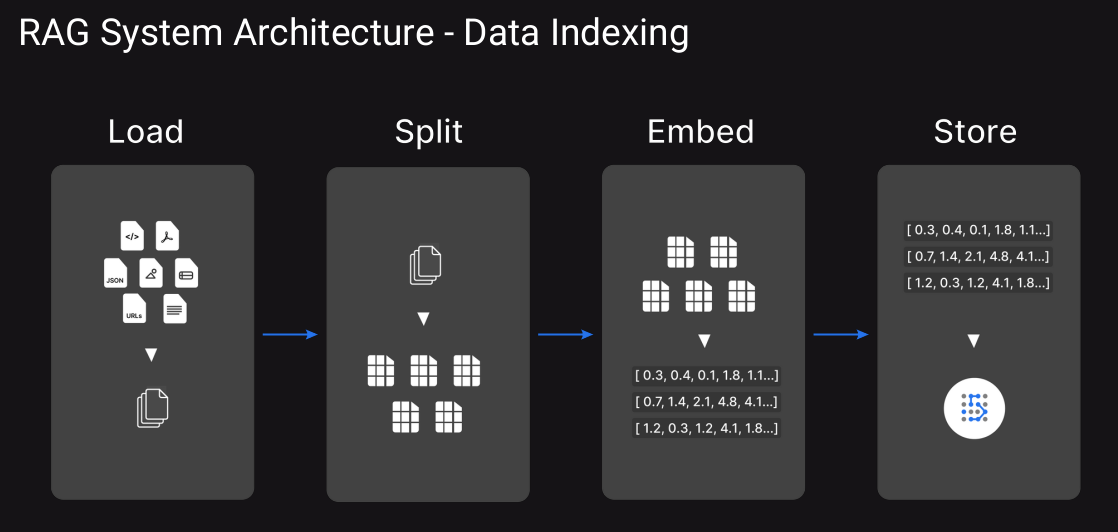
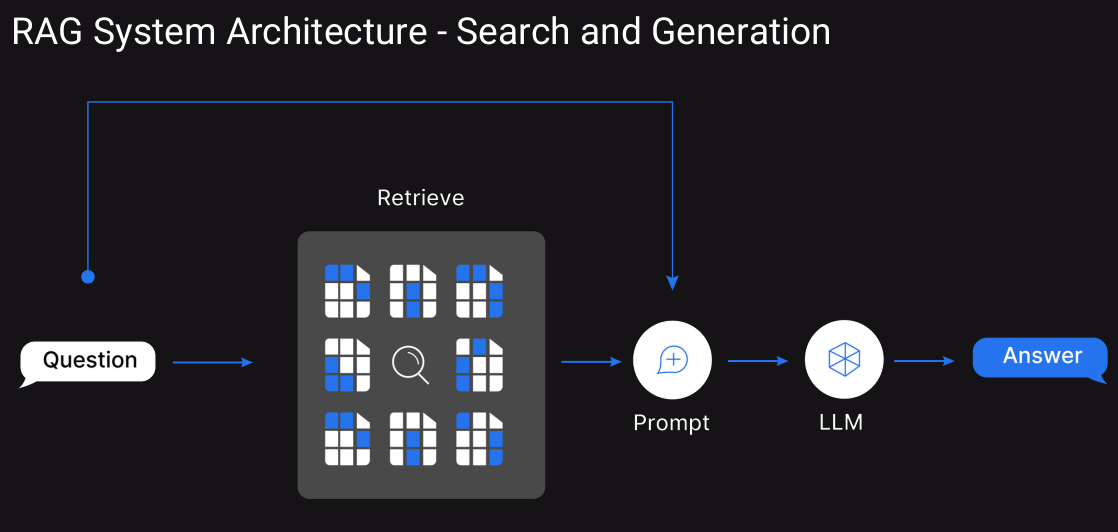
These images depict the architecture of a Retrieval-Augmented Generation (RAG) system. The various components are as follows:
This line of code installs the LangChain and OpenAI libraries. LangChain is critical for handling text data and embedding, while OpenAI provides access to state-of-the-art Large Language Models (LLMs). This installation step is essential for setting up the required tools for RAG.
!pip install langchain openai
!pip install -q -U faiss-cpu tiktoken
import osIt is best practice to store the API keys in the .env file and load them using the below code:
from dotenv import load_dotenv
load_dotenv('/.env')from langchain_community.document_loaders import WebBaseLoader
yolo_nas_loader = WebBaseLoader("https://deci.ai/blog/yolo-nas-object-detection-foundation-model/").load()
decicoder_loader = WebBaseLoader("https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/#:~:text=DeciCoder's%20unmatched%20throughput%20and%20low,re%20obsessed%20with%20AI%20efficiency.").load()
yolo_newsletter_loader = WebBaseLoader("https://deeplearningdaily.substack.com/p/unleashing-the-power-of-yolo-nas").load()We will use any text splitter to split the data into smaller chunks. Here we will use CharacterTextSplitter.
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=500,
chunk_overlap=0,
is_separator_regex=False,)Let us apply the text_splitter for the data as below to split the data into chunks.
yolo_nas_chunks = text_splitter.split_documents(yolo_nas_loader)
decicoder_chunks = text_splitter.split_documents(decicoder_loader)
yolo_newsletter_chunks = text_splitter.split_documents(yolo_newsletter_loader)from langchain_openai import OpenAIEmbeddings
from langchain.embeddings.cache import CacheBackedEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.storage import LocalFileStore
store = LocalFileStore("./cachce/")
# create an embedder
core_embeddings_model = OpenAIEmbeddings()
embedder = CacheBackedEmbeddings.from_bytes_store(
core_embeddings_model,
store,
namespace = core_embeddings_model.model
)
# store embeddings in vector store
vectorstore = FAISS.from_documents(yolo_nas_chunks, embedder)
vectorstore.add_documents(decicoder_chunks)
vectorstore.add_documents(yolo_newsletter_chunks)
# instantiate a retriever
retriever = vectorstore.as_retriever()from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
# this formats the docs returned by the retriever
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# prompt to send to the LLM
prompt = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt_template = ChatPromptTemplate.from_template(prompt)
llm = ChatOpenAI(model='gpt-4o-mini', streaming=True)
# This code defines a chain where input documents are first formatted, then passed through a prompt template, and finally processed by an LLM.
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt_template
| llm
)
# This code creates a parallel process: one retrieves the context (using a retriever), and the other passes the question through unchanged. The results are then combined and assigned to the variable `answer` using the `rag_chain_from_docs` processing chain.
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)The code sets up a RetrievalQA chain, a critical part of the RAG system, by combining an OpenAIChat language model (LLM) with a retriever and callback handler.
It sends various user queries to the RAG system, prompting it to retrieve contextually relevant information.
After processing the queries, the RAG system generates and returns contextually rich and accurate responses. The responses are printed on the console.
# This is to generate response with RAG system
response = rag_chain_with_source.invoke(
"What does Neural Architecture Search have to do with how Deci creates its models?")
print(response['answer'].content)
print(response['context'])
response = rag_chain_with_source.invoke("What is DeciCoder")
print(response['answer'].content)
print(response['context'])
response = rag_chain_with_source.invoke(
"Write a blog about Deci and how it used NAS to generate YOLO-NAS and DeciCoder")
print(response['answer'].content)
print(response['context'])
This code exemplifies how RAG and LangChain can enhance information retrieval and generation in AI applications.
Explore these articles to know more about RAG and its applications:
Retrieval-Augmented Generation (RAG) represents a transformative leap in artificial intelligence. It seamlessly integrates Large Language Models (LLMs) with external knowledge sources, addressing the limitations of LLMs’ parametric memory.
RAG’s ability to access real-time data, coupled with improved contextualization, enhances the relevance and accuracy of AI-generated responses. Its updatable memory ensures responses are current without extensive model retraining. RAG also offers source citations, bolstering transparency and reducing data leakage. In summary, RAG empowers AI to provide more accurate, context-aware, and reliable information, promising a brighter future for AI applications across industries.
If you want to master RAG and other generative AI concepts then our Pinnacle Program is the right fit for you. Checkout the program today!
A. Retrieval-augmented generation (RAG) combines generation and retrieval models in AI. It enhances text generation by retrieving relevant information from a large dataset before generating responses.
A. The RAG approach in General AI integrates retrieval-based methods with generative models. It leverages pre-existing knowledge for more accurate and contextually relevant text generation tasks.
A. The RAG system in AI uses a dual-model architecture where a retrieval model fetches relevant information, guiding a generative model to produce coherent and informed responses or outputs.
A. RAG (retrieval-augmented generation) and LLM (large language model) represent advancements in AI. RAG combines retrieval and generation, while LLM refers to models like GPT that process and generate text.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,







