In the ever-evolving world of artificial intelligence, Moreover, where algorithms mimic the human brain’s ability to learn from data, Recurrent Neural Networks (RNNs) have emerged as a powerful deep learning algorithm for processing sequential data. However, RNNs struggle with long-term dependencies within sequences. This is where Gated Recurrent Units (GRUs) come in. As a type of RNN equipped with a specific learning algorithm, GRUs address this limitation by utilizing gating mechanisms to control information flow, making them a valuable tool for various tasks in machine learning.
Note: If you are more interested in learning concepts in an Audio-Visual format, We have this entire article explained in the video below. If not, you may continue reading.
GRU or Gated recurrent unit is an advancement of the standard RNN i.e recurrent neural network. It was introduced by Kyunghyun Cho et al in the year 2014.
GRUs are very similar to Long Short Term Memory(LSTM). Just like LSTM, GRU uses gates to control the flow of information. They are relatively new as compared to LSTM. This is the reason they offer some improvement over LSTM and have simpler architecture.
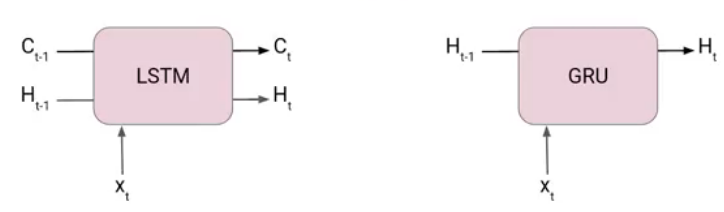
Another Interesting thing about GRU network is that, unlike LSTM, it does not have a separate cell state (Ct). It only has a hidden state(Ht). Due to the simpler architecture, GRUs are faster to train.
In case you are unaware of the LSTM network, I will suggest you go through the following article-Introduction to Long Short term Memory(LSTM).
Here are the limitations of standard RNNs in bullet points:
There are various types of recurrent neural network to solve the issues with standard RNN, GRU is one of them. Here’s how GRUs address the limitations of standard RNNs:
Now lets’ understand how GRU works. Here we have a GRU cell which more or less similar to an LSTM cell or RNN cell.
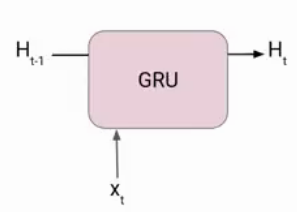
At each timestamp t, it takes an input Xt and the hidden state Ht-1 from the previous timestamp t-1. Later it outputs a new hidden state Ht which again passed to the next timestamp.
Now there are primarily two gates in a GRU as opposed to three gates in an LSTM cell. The first gate is the Reset gate and the other one is the update gate.
The Reset Gate is responsible for the short-term memory of the network i.e the hidden state (Ht). Here is the equation of the Reset gate.
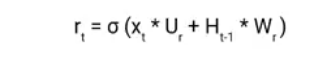
If you remember from the LSTM gate equation it is very similar to that. The value of rt will range from 0 to 1 because of the sigmoid function. Here Ur and Wr are weight matrices for the reset gate.
Similarly, we have an Update gate for long-term memory and the equation of the gate is shown below.
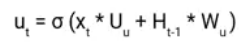
The only difference is of weight metrics i.e Uu and Wu.
Now let’s see the functioning of these gates in detail. To find the Hidden state Ht in GRU, it follows a two-step process. The first step is to generate what is known as the candidate hidden state. As shown below
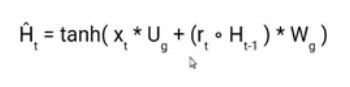
It takes in the current input and the hidden state from the previous timestamp t-1 which is multiplied by the reset gate output rt. Later passed this entire information to the tanh function, the resultant value is the candidate’s hidden state.
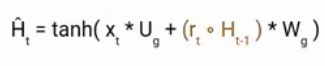
The most important part of this equation is how we are using the value of the reset gate to control how much influence the previous hidden state can have on the candidate state.
If the value of rt is equal to 1 then it means the entire information from the previous hidden state Ht-1 is being considered. Likewise, if the value of rt is 0 then that means the information from the previous hidden state is completely ignored.
Once we have the candidate state, it is used to generate the current hidden state Ht. It is where the Update gate comes into the picture. Now, this is a very interesting equation, instead of using a separate gate like in LSTM and GRU Architecture we use a single update gate to control both the historical information which is Ht-1 as well as the new information which comes from the candidate state.
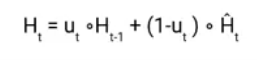
Now assume the value of ut is around 0 then the first term in the equation will vanish which means the new hidden state will not have much information from the previous hidden state. On the other hand, the second part becomes almost one that essentially means the hidden state at the current timestamp will consist of the information from the candidate state only.
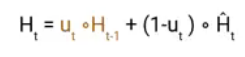
Similarly, if the value of ut is on the second term will become entirely 0 and the current hidden state will entirely depend on the first term i.e the information from the hidden state at the previous timestamp t-1.
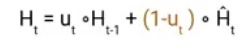
Hence we can conclude that the value of ut is very critical in this equation and it can range from 0 to 1.
In case, you are interested to know more about LSTM and GRU Architecture I suggest you read this Paper.
Here are some applications of GRUs where their ability to handle sequential data shines:
GRUs can analyze the sequence of audio signals in speech to transcribe it into text. They can be particularly effective in handling variations in speech patterns and accents.
GRUs can analyze historical data like sales figures, website traffic, or stock prices to predict future trends. Their ability to capture long-term dependencies makes them well-suited for forecasting tasks.
GRUs can identify unusual patterns in sequences of data, which can be helpful for tasks like fraud detection or network intrusion detection.
GRUs can be used to generate musical pieces by analyzing sequences of notes and chords. They can learn the patterns and styles of different musical genres and create new music that sounds similar.
These are just a few examples, and the potential applications of GRUs continue to grow as researchers explore their capabilities in various fields.
Gated Recurrent Units (GRUs) represent a significant advancement in recurrent neural networks, addressing the limitations of standard RNNs. With their efficient gating mechanisms, GRUs effectively manage long-term dependencies in sequential data, making them valuable for various applications in natural language processing, speech recognition, and time series forecasting. While offering advantages like faster training and effective memory management, GRUs also have limitations such as potential overfitting and reduced interpretability. As AI continues to evolve, GRUs remain a powerful tool in the machine learning toolkit, balancing efficiency and performance for sequential data processing tasks.
A. A Gated Recurrent Unit (GRU) is a type of recurrent neural network (RNN) architecture that uses gating mechanisms to manage and update information flow within the network.
A. GRU is utilized for sequential data tasks such as speech recognition, language translation, and time series prediction. It efficiently captures dependencies over time while mitigating vanishing gradient issues.
A. LSTM (Long Short-Term Memory) and GRU are both RNN variants with gating mechanisms, but GRU has a simpler architecture with fewer parameters and may converge faster with less data. LSTM, on the other hand, has more parameters and better long-term memory capabilities.
A. The GRU methodology involves simplifying the LSTM architecture by combining the forget and input gates into a single update gate. This streamlines information flow and reduces the complexity of managing long-term dependencies in sequential data.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Nicely explained. Thanks.
Very Understandable Explanations.. Thanks