This article was published as a part of the Data Science Blogathon.

Hey Folks!
I have decided to write a series of articles explaining all the basic to the advanced concepts of NLP using python. So if you want to learn NLP by reading it and coding, this will be a perfect series of articles for you.
Target Audience:
Anyone new or zero in NLP can start with us and follow this series of articles.
Prerequisite: Python Basic Understanding
Libraries Used: Keras, Tensorflow, Scikit learn, NLTK, Glove, etc.
1. Raw data processing (Data cleaning)
2. Tokenization and StopWords
3. Feature Extraction techniques
4. Topic Modelling and LDA
5.Word2Vec (word embedding)
6. Continuous Bag-of-words(CBOW)
7. Global Vectors for Word Representation (GloVe)
8. text Generation,
9. Transfer Learning
All of the topics will be explained using codes of python and popular deep learning and machine learning frameworks, such as sci-kit learn, Keras, and TensorFlow.
Natural Language Processing is a part of computer science that allows computers to understand language naturally, as a person does. This means the laptop will comprehend sentiments, speech, answer questions, text summarization, etc. We will not be much talking about its history and evolution. If you are interested, prefer this link.
The raw text data comes directly after the various sources are not cleaned. We apply multiple steps to make data clean. Un-cleaned text data contains useless information that deviates results, so it’s always the first step to clean the data. Some standard preprocessing techniques should be applied to make data cleaner. Cleaned data also prevent models from overfitting.
In this article, we will see the following topics under text processing and exploratory data analysis.
I am converting the raw text data into a pandas data frame and performing various data cleaning techniques.
import pandas as pd
text = [‘This is the NLP TASKS ARTICLE written by ABhishek Jaiswal** ‘,’IN this article I”ll be explaining various DATA-CLEANING techniques’,
‘So stay tuned for FURther More &&’,'Nah I don"t think he goes to usf, he lives around']
df = pd.DataFrame({'text':text})
Output:
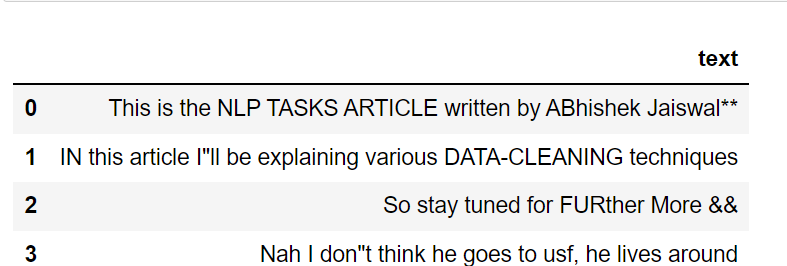
The method lower()converts all uppercase characters into lowercase and returns.
Applying lower() method using lambda function
df['lower'] = df['text'].apply(lambda x: " ".join(x.lower() for x in x.split()))
Removing punctuation(*,&,%#@#()) is a crucial step since punctuation doesn’t add any extra information or value to our data. Hence, removing punctuation reduces the data size; therefore, it improves computational efficiency.
This step can be done using the Regex or Replace method.

string.punctuation returns a string containing all punctuations.

Removing punctuation using regular expressions:

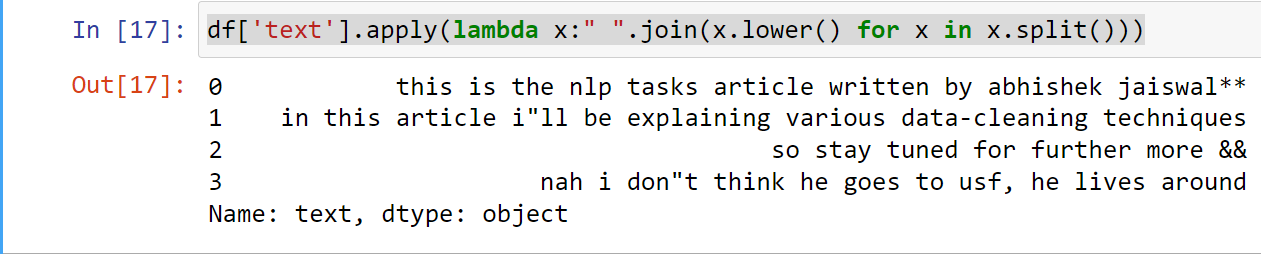
Words that frequently occur in sentences and carry no significant meaning in sentences. These are not important for prediction, so we remove stopwords to reduce data size and prevent overfitting. Note: Before filtering stopwords, make sure you lowercase the data since our stopwords are lowercase.
Using the NLTK library, we can filter out our Stopwords from the dataset.
# !pip install nltk
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
allstopwords = stopwords.words('english')
df.lower.apply(lambda x: " ".join(i for i in x.split() if i not in allstopwords))
Most of the text data extracted in customer reviews, blogs, or tweets have some chances of spelling mistakes.
Correcting spelling mistakes improves model accuracy.
There are various libraries to fix spelling mistakes, but the most convenient method is to use a text blob.
The method correct() works on text blob objects and corrects the spelling mistakes.
#Install textblob library !pip install textblob from textblob import TextBlob

Tokenization means splitting text into meaningful unit words. There are sentence tokenizers as well as word tokenizers.
Sentence tokenizer splits a paragraph into meaningful sentences, while word tokenizer splits a sentence into unit meaningful words. Many libraries can perform tokenization like SpaCy, NLTK, and TextBlob.
Splitting a sentence on space to get individual unit words can be understood as tokenization.
import nltk mystring = "My favorite animal is cat" nltk.word_tokenize(mystring)
mystring.split(" ")
output:
[‘My’, ‘favorite’, ‘animal’, ‘is’, ‘cat’]
Stemming is converting words into their root word using some set of rules irrespective of meaning. I.e.,
The simplest way to perform stemming is to use NLTK or a TextBlob library.
NLTK provides various stemming techniques, i.e. Snowball, PorterStemmer; different technique follows different sets of rules to convert words into their root word.
import nltk from nltk.stem import PorterStemmer st = PorterStemmer() df['text'].apply(lambda x:" ".join([st.stem(word) for word in x.split()]))
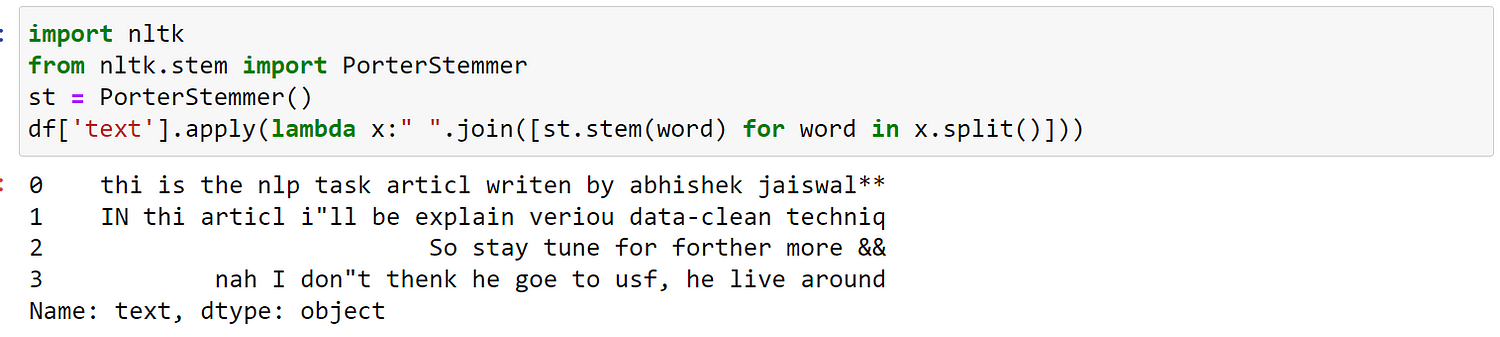
“article” is stemmed into “articl“, “lives“ — -> “live“.
Lemmatization is converting words into their root word using vocabulary mapping. Lemmatization is done with the help of part of speech and its meaning; hence it doesn’t generate meaningless root words. But lemmatization is slower than stemming.
Ie. leafs Stemmed to. leaves stemmed to leav while leafs , leaves lemmatized to leaf
Lemmatization can be done using NLTK, TextBlob library.
Lemmatize the whole dataset.

So far, we have seen the various text preprocessing techniques that must be done after getting the raw data. After cleaning our data, we now can perform exploratory data analysis and explore and understand the text data.
Counting the unique words in our data gives an idea about our data’s most frequent, least frequent terms. Often we drop the least frequent comments to make our model training more generalized.
nltk provides Freq_dist class to calculate word frequency, and it takes a bag of words as input.
all_words = []
for sentence in df['processed']:
all_words.extend(sentence.split())
all_words Contain all the words available in our dataset. We often call it vocabulary.
import nltk nltk.Freq_dist(all_words)

This shows the word as key and the number of occurrences in our data as value.
Wordcloud is the pictorial representation of the word frequency of the dataset.WordCloud is easier to understand and gives a better idea about our textual data.
The library wordcloud Let us create a word cloud in a few lines of code.
importing libraries :
from wordcloud import WordCloud from wordcloud import STOPWORDS import matplotlib.pyplot as plt
We can draw a word cloud using text containing all the words of our data.
words = []
for message in df['processed']:
words.extend([word for word in message.split() if word not in STOPWORDS])
wordcloud = WordCloud(width = 1000, height = 500).generate(" ".join(words))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

background_color = 'white' using this parameter, we can change the background colour of the word cloud.collocations = False Keeping it as False will ignore the collocation words. Collocations are those words that are formed by those words which occur together. I.e. pay attention, home works, etc.Note : Before making the word cloud always remove the stopwords.
In this article, we saw various necessary techniques for textual data preprocessing. After data cleaning, we performed exploratory data analysis using word cloud and created a word frequency.
In the second article of this series, we will learn the following topics:
1.One Hot encoding2.Count vectorizer3.Term Frequency-Inverse Document Frequency (TF-IDF)4.N-grams5.Co-occurrence matrix6.Word embedding Recipe7.Implementing fastText
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Hi, I'm starting out in NLP and I'm following the example of your article, which I found very interesting. But when I get to the point where we import the 'Word' library it gives me an error that I can't get past. Any help from you would be greatly appreciated. I attach my code with the error. Thank you. --------------------------------------------------------------------------- KeyError Traceback (most recent call last) File ~\Envs\Natural1\lib\site-packages\pandas\core\indexes\base.py:3361, in Index.get_loc(self, key, method, tolerance) 3360 try: -> 3361 return self._engine.get_loc(casted_key) 3362 except KeyError as err: File ~\Envs\Natural1\lib\site-packages\pandas\_libs\index.pyx:76, in pandas._libs.index.IndexEngine.get_loc() File ~\Envs\Natural1\lib\site-packages\pandas\_libs\index.pyx:108, in pandas._libs.index.IndexEngine.get_loc() File pandas\_libs\hashtable_class_helper.pxi:5198, in pandas._libs.hashtable.PyObjectHashTable.get_item() File pandas\_libs\hashtable_class_helper.pxi:5206, in pandas._libs.hashtable.PyObjectHashTable.get_item() KeyError: 'processed' The above exception was the direct cause of the following exception: KeyError Traceback (most recent call last) Input In [56], in 1 import textblob 2 from textblob import Word ----> 3 df['processed'].apply(lambda x: " ".join([Word(word).lematize() for word in x.split()])) File ~\Envs\Natural1\lib\site-packages\pandas\core\frame.py:3458, in DataFrame.__getitem__(self, key) 3456 if self.columns.nlevels > 1: 3457 return self._getitem_multilevel(key) -> 3458 indexer = self.columns.get_loc(key) 3459 if is_integer(indexer): 3460 indexer = [indexer] File ~\Envs\Natural1\lib\site-packages\pandas\core\indexes\base.py:3363, in Index.get_loc(self, key, method, tolerance) 3361 return self._engine.get_loc(casted_key) 3362 except KeyError as err: -> 3363 raise KeyError(key) from err 3365 if is_scalar(key) and isna(key) and not self.hasnans: 3366 raise KeyError(key) KeyError: 'processed'