In this article, we will look into the fundamental principles and components that constitute the bedrock of CNNs. In this article, we unravel the intricate layers of neural networks shaping the future of artificial intelligence. Understanding the basics of CNN is not just a step; it’s a leap into deep learning, where the transformative power of Convolutional Neural Networks (CNNs) takes center stage. Join us as we demystify the workings of CNNs, exploring their architecture, operations, and profound impact on reshaping the landscape of deep learning. Whether you’re a novice eager to grasp the essentials or a seasoned practitioner looking to deepen your knowledge, this exploration of the Basics of CNN in Deep Learning promises to enlighten and inspire.
This article was published as a part of the Data Science Blogathon.
Convolutional Neural Networks also known as CNNs or ConvNets, are a type of feed-forward artificial neural network whose connectivity structure is inspired by the organization of the animal visual cortex. Small clusters of cells in the visual cortex are sensitive to certain areas of the visual field. Individual neuronal cells in the brain respond or fire only when certain orientations of edges are present. Some neurons activate when shown vertical edges, while others fire when shown horizontal or diagonal edges. A convolutional neural network is a type of artificial neural network used in deep learning to evaluate visual information. These networks can handle a wide range of tasks involving images, sounds, texts, videos, and other media. Professor Yann LeCunn of Bell Labs created the first successful convolution networks in the late 1990s.

Convolutional Neural Networks (CNNs) have an input layer, an output layer, numerous hidden layers, and millions of parameters, allowing them to learn complicated objects and patterns. It uses convolution and pooling processes to sub-sample the given input before applying an activation function, where all of them are hidden layers that are partially connected, with the completely connected layer at the end resulting in the output layer. The output shape is similar to the size of the input image.
Convolution is the process of combining two functions to produce the output of the other function. The input image is convoluted with the application of filters in CNNs, resulting in a Feature map. Filters are weights and biases that are randomly generated vectors in the network. Instead of having individual weights and biases for each neuron, CNN uses the same weights and biases for all neurons. Many filters can be created, each of which catches a different aspect from the input. Kernels are another name for filters.
In convolutional neural networks (CNNs), the primary components are convolutional layers. These layers typically involve input vectors, like an image, filters (or feature detectors), and output vectors, which are often referred to as feature maps. As the input, such as an image, traverses through a convolutional layer, it undergoes abstraction into a feature map, also known as an activation map. This process involves the convolution operation, which enables the detection of more complex features within the image. Additionally, rectified linear units (ReLU) are commonly used as activation functions within these layers to introduce non-linearity into the network. Furthermore, CNNs often employ pooling operations to reduce the spatial dimensions of the feature maps, leading to a more manageable output volume. Overall, convolutional layers play a crucial role in extracting meaningful features from the input data, making them fundamental in tasks such as image classification and natural language processing, among others, within the realm of machine learning models.
Feature Map = Input Image x Feature Detector
The input is convolved by convolutional layers, which then pass the output to the next layer. This is analogous to a neuron’s response to a single stimulus in the visual cortex. Each convolutional neuron only processes data for the receptive field it is assigned to.
A convolution is a grouping function in mathematics. Convolution occurs in CNNs when two matrices (rectangular arrays of numbers arranged in columns and rows) are combined to generate a third matrix.
In the convolutional layers of a CNN, these convolutions are used to filter input data and find information.
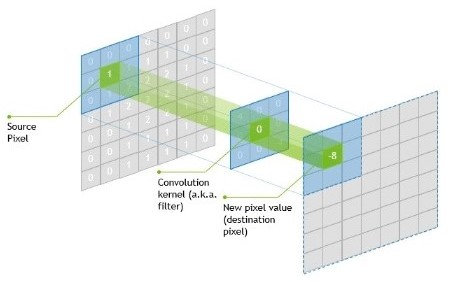
The kernel’s centre element is put above the source pixel. After that, the source pixel is replaced with a weighted sum of itself and neighboring pixels.
Parameter sharing and local connectivity are two principles used in CNNs. All neurons in a feature map share weights, which is known as parameter sharing. Local connection refers to the idea of each neural being connected to only a part of the input image (as opposed to a neural network in which all neurons are fully connected). This reduces the number of parameters in the system and speeds up the calculation.
Padding and stride have an impact on how the convolution procedure is carried out. They can be used to increase or decrease the dimensions (height and width) of input/output vectors.
It is a term used in convolutional neural networks to describe how many pixels are added to an image when it is processed by the CNN kernel. If the padding in a CNN is set to zero, for example, every pixel value-added will have the value zero. If the zero padding is set to one, a one-pixel border with a pixel value of zero will be added to the image.
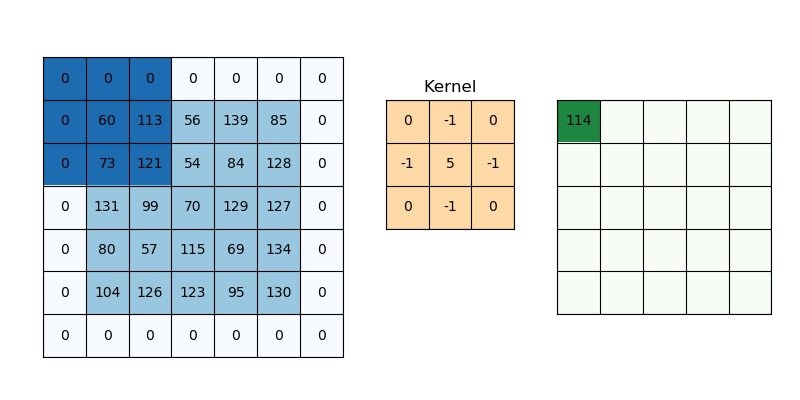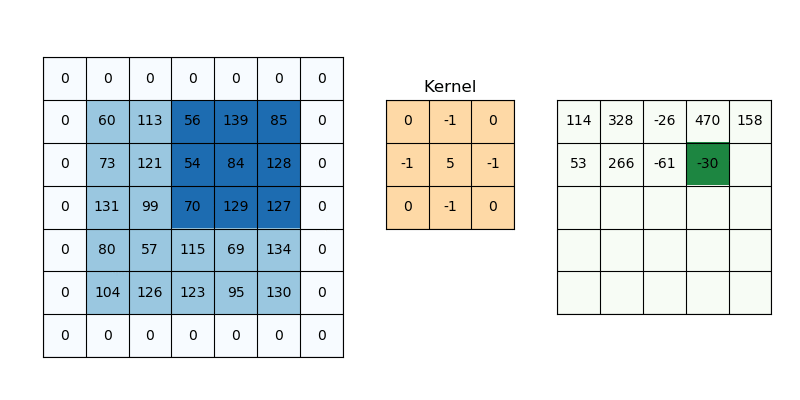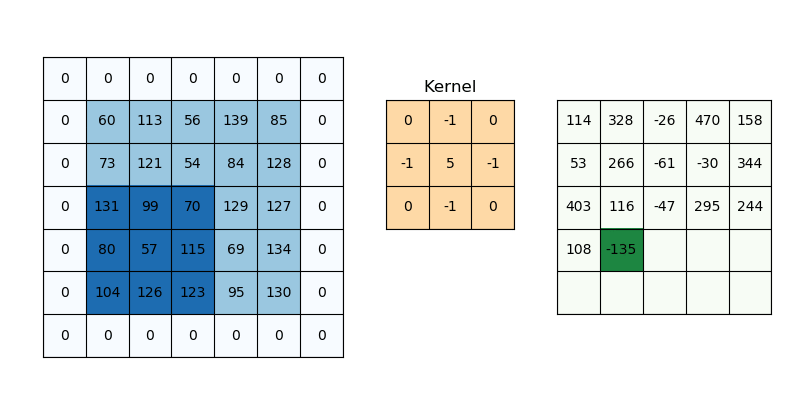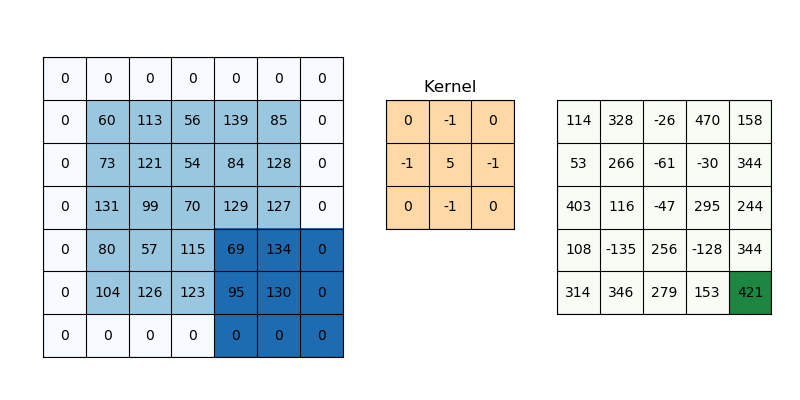
Padding works by increasing the processing region of a convolutional neural network. The kernel is a neural network filter that moves through a picture, scanning each pixel and turning the data into a smaller or bigger format. Padding is added to the image frame to aid the kernel in processing the image by providing more room for the kernel to cover the image. Adding padding to a CNN-processed image provides for more accurate image analysis.
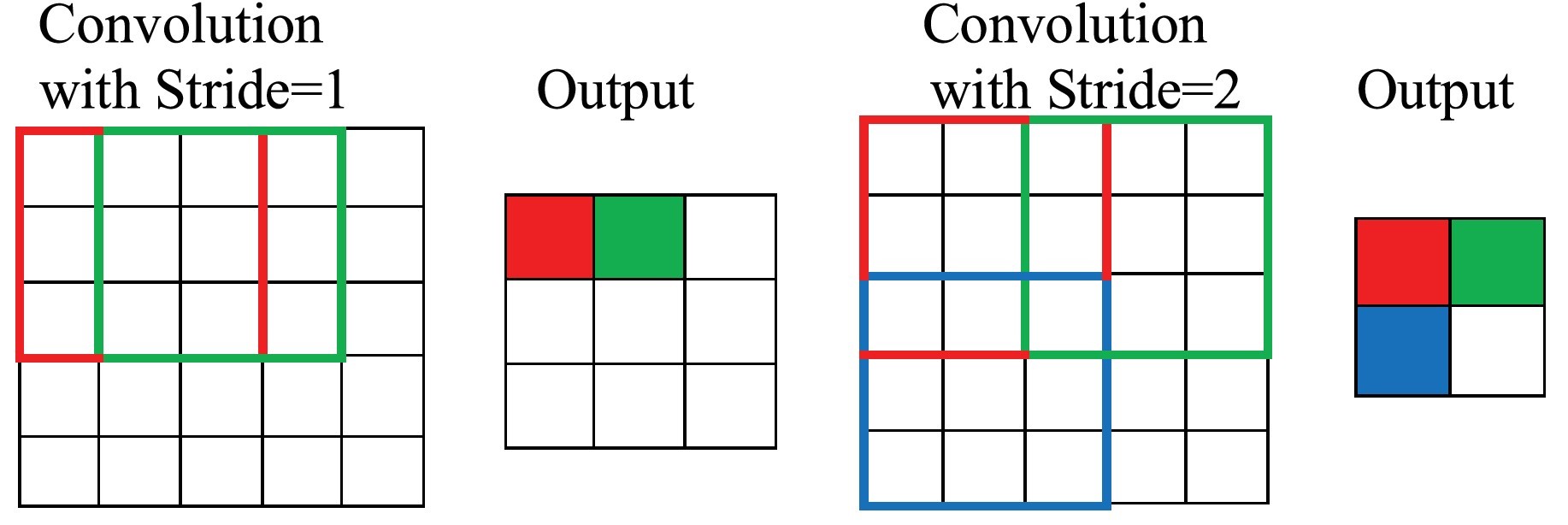
Stride determines how the filter convolves over the input matrix, i.e. how many pixels shift. When stride is set to 1, the filter moves across one pixel at a time, and when the stride is set to 2, the filter moves across two pixels at a time. The smaller the stride value, the smaller the output, and vice versa.
Its purpose is to gradually shrink the representation’s spatial size to reduce the number of parameters and computations in the network. The pooling layer treats each feature map separately.
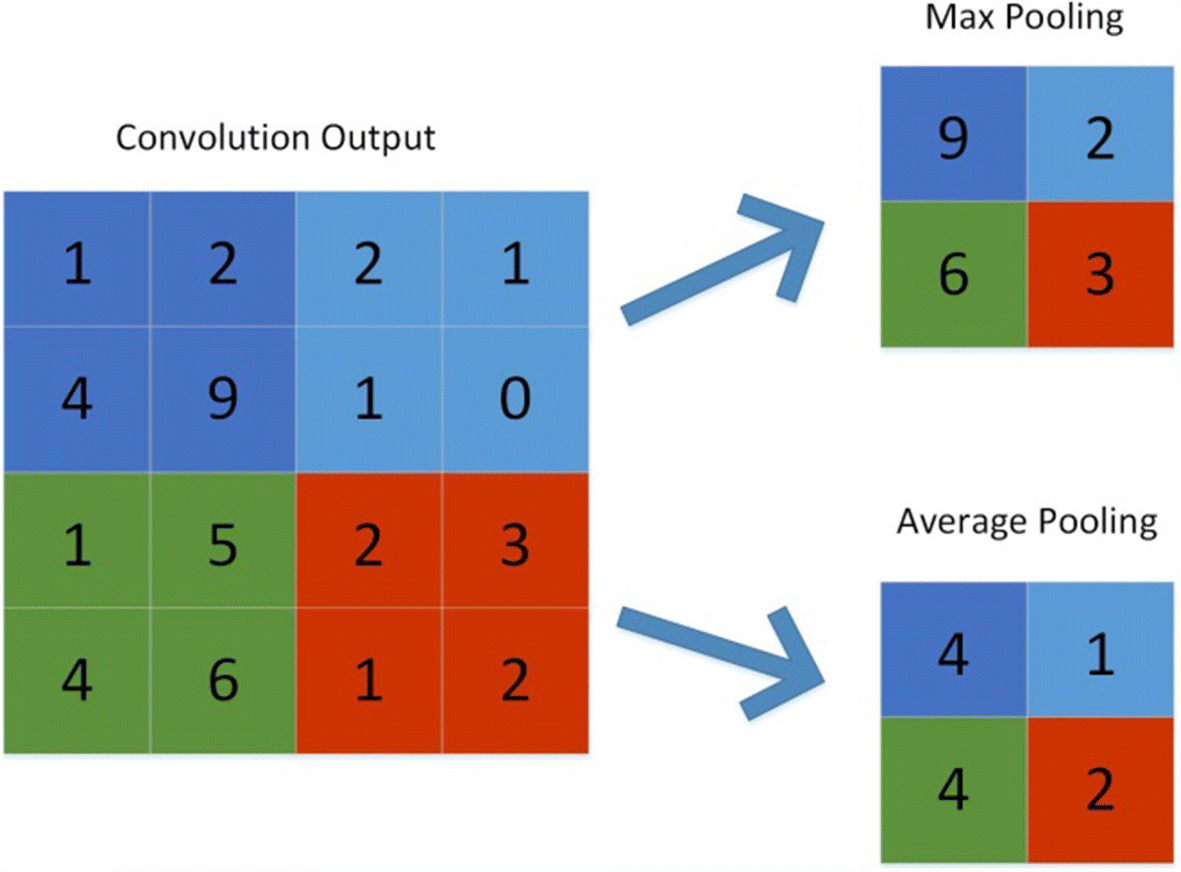
The following are some methods for pooling:
Pooling gradually reduces the spatial dimension of the representation to reduce the number of parameters and computations in the network, as well as to prevent overfitting. If there is no pooling, the output has the same resolution as the input.
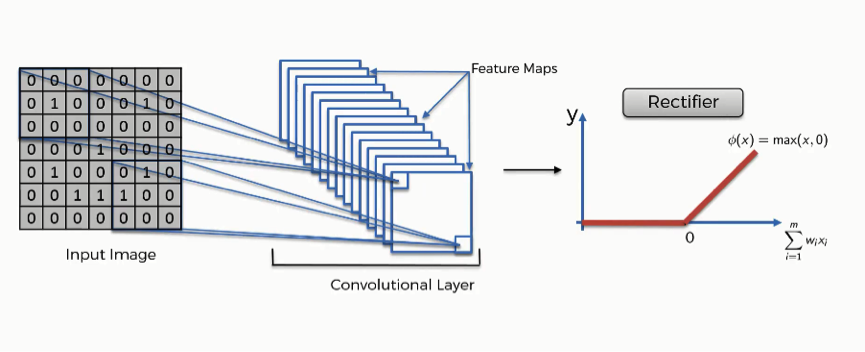
The rectified linear activation function, or ReLU for short, is a piecewise linear function that, if the input is positive, outputs the input directly; else, it outputs zero. Because a model that utilizes it is quicker to train and generally produces higher performance, it has become the default activation function for many types of neural networks.
At the end of CNN, there is a Fully connected layer of neurons. As in conventional Neural Networks, neurons in a fully connected layer have full connections to all activations in the previous layer and work similarly. After training, the feature vector from the fully connected layer is used to classify images into distinct categories. Every activation unit in the next layer is coupled to all of the inputs from this layer. Overfitting occurs because all of the parameters are occupied in the fully-connected layer. Overfitting can be reduced using a variety of strategies, including dropout.
Soft-max is an activation layer that is typically applied to the network’s last layer, which serves as a classifier. This layer is responsible for categorizing provided input into distinct types. A network’s non-normalized output is mapped to a probability distribution using the softmax function.
import NumPy as np
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import TensorFlow as tf
tf.compat.v1.set_random_seed(2019)(X_train,Y_train),(X_test,Y_test) = keras.datasets.mnist.load_data()X_train = X_train / 255
X_test = X_test / 255
#flatenning
X_train_flattened = X_train.reshape(len(X_train), 28*28)
X_test_flattened = X_test.reshape(len(X_test), 28*28)model = keras.Sequential([
keras.layers.Dense(10, input_shape=(784,), activation='sigmoid')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(X_train_flattened, Y_train, epochs=5)Epoch 1/5
1875/1875 [==============================] - 8s 4ms/step - loss: 0.7187 - accuracy: 0.8141
Epoch 2/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.3122 - accuracy: 0.9128
Epoch 3/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2908 - accuracy: 0.9187
Epoch 4/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2783 - accuracy: 0.9229
Epoch 5/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2643 - accuracy: 0.9262Sliding Filters: Imagine a small window sliding over an image. This window has some numbers in it called weights. As it moves, it multiplies these weights with the numbers in the image underneath, and adds them up to make a new number. Convolution layers extract features. Finding Patterns: By adjusting these weights, the window learns to recognize patterns like edges or textures. For example, it might learn to detect a horizontal line or a diagonal edge. Sharing Knowledge: Instead of having different windows all over the image, we use the same window everywhere. This saves a lot of memory and helps the network learn faster. Convolution neural networks utilize this technique.
Building a Picture: As we slide these windows over the image, we build up a new picture. Each new picture highlights different patterns that we’ve learned. This process is crucial for image recognition and computer vision tasks.
Making Things Smaller: Sometimes, we don’t need all the details. So, we shrink the picture by combining nearby numbers. This makes things faster and helps us focus on the most important parts. This is particularly useful in medical image analysis.
Adding Some Curves: After all these operations, we apply a simple rule to make our picture more expressive. This helps us capture complicated relationships between the patterns we’ve found. This step is common in convolutional neural networks and other deep learning models. By repeating these steps with different patterns and pictures, we can teach a computer to recognize all sorts of things in images, like cats, cars, or even emotions on people’s faces! This involves earlier layers learning basic features and later layers combining them to recognize entire images.
The goal of this article was to provide an overview of convolutional neural networks and their main applications. These networks, in general, produce excellent classification and recognition results. They’re also used to decode audio, text, and video. If the task at hand is to find a pattern in a series, convolutional networks are an excellent choice.
Read more articles about CNNs here.
A. Convolutional Neural Networks (CNNs) are a class of deep learning models designed for image processing. They employ convolutional layers to automatically learn hierarchical features from input images.
A. The basic principle of CNN lies in feature learning through convolutional layers. These layers apply filters to input data, extracting meaningful features and capturing spatial hierarchies for accurate pattern recognition.
A. The four key components of CNN are convolutional layers, pooling layers, fully connected layers, and activation functions. These elements work together to enable feature extraction, dimension reduction, and classification in image data.
A. CNN operations include convolution, where filters detect features, pooling to downsample and retain essential information, flattening to convert data for fully connected layers, and activation functions for introducing non-linearity in the model’s learning process.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Thanks, Debasish. Clear and Concise.
Thank You Debasish for making concepts clear with visualization.