This article was published as a part of the Data Science Blogathon
Hello, Welcome to the world of EDA using Data Visualization. Exploratory data analysis is a way to better understand your data which helps in further Data preprocessing. And data visualization is key, making the exploratory data analysis process streamline and easily analyzing data using wonderful plots and charts.

Data Visualization represents the text or numerical data in a visual format, which makes it easy to grasp the information the data express. We, humans, remember the pictures more easily than readable text, so Python provides us various libraries for data visualization like matplotlib, seaborn, plotly, etc. In this tutorial, we will use Matplotlib and seaborn for performing various techniques to explore data using various plots.
Creating Hypotheses, testing various business assumptions while dealing with any Machine learning problem statement is very important and this is what EDA helps to accomplish. There are various tootle and techniques to understand your data, And the basic need is you should have the knowledge of Numpy for mathematical operations and Pandas for data manipulation.
We will use a very popular Titanic dataset with which everyone is familiar with and you can download it from here.
Now lets us start exploring data and study different data visualization plots with different types of data. And for demonstrating some of the techniques we will also use an inbuilt dataset of seaborn as tips data which explains the tips each waiter gets from different customers.
let’s get started by importing libraries and loading Data
import numpy as np
import pandas pd
import matplotlib.pyplot as plt
import seaborn as sns
from seaborn import load_dataset
#titanic dataset
data = pd.read_csv("titanic_train.csv")
#tips dataset
tips = load_dataset("tips")
Univariate analysis is the simplest form of analysis where we explore a single variable. Univariate analysis is performed to describe the data in a better way. we perform Univariate analysis of Numerical and categorical variables differently because plotting uses different plots.
A variable that has text-based information is referred to as categorical variables. let’s look at various plots which we can use for visualizing Categorical data.
Countplot is basically a count of frequency plot in form of a bar graph. It plots the count of each category in a separate bar. When we use the pandas’ value counts function on any column, It is the same visual form of the value counts function. In our data-target variable is survived and it is categorical so let us plot a countplot of this.
The pie chart is also the same as the countplot, only gives you additional information about the percentage presence of each category in data means which category is getting how much weightage in data. let us check about the Sex column, what is a percentage of Male and Female members traveling.
data['Sex'].value_counts().plot(kind="pie", autopct="%.2f")
plt.show()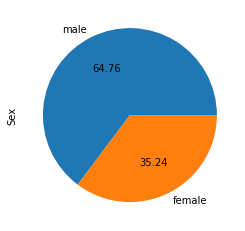
Analyzing Numerical data is important because understanding the distribution of variables helps to further process the data. Most of the time you will find much inconsistency with numerical data so do explore numerical variables.
A histogram is a value distribution plot of numerical columns. It basically creates bins in various ranges in values and plots it where we can visualize how values are distributed. We can have a look where more values lie like in positive, negative, or at the center(mean). Let’s have a look at the Age column.
plt.hist(data['Age'], bins=5)
plt.show()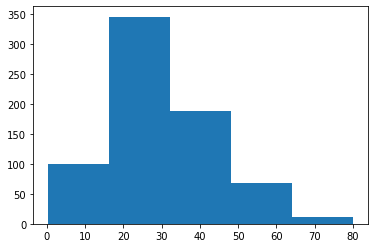
Distplot is also known as the second Histogram because it is a slight improvement version of the Histogram. Distplot gives us a KDE(Kernel Density Estimation) over histogram which explains PDF(Probability Density Function) which means what is the probability of each value occurring in this column. If you have study statistics before then definitely you should know about PDF function.
sns.distplot(data['Age']) plt.show()
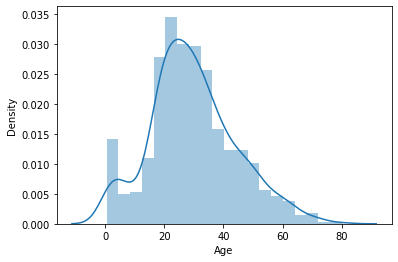
Boxplot is a very interesting plot that basically plots a 5 number summary. to get 5 number summary some terms we need to describe.
IQR = Q3 - Q1 Lower_boundary = Q1 - 1.5 * IQR Upper_bounday = Q3 + 1.5 * IQR
Here Q1 and Q3 is 1st quantile(25th percentile) and 3rd Quantile(75th percentile)
We have study about various plots to explore single categorical and numerical data. Bivariate Analysis is used when we have to explore the relationship between 2 different variables and we have to do this because, in the end, our main task is to explore the relationship between variables to build a powerful model. And when we analyze more than 2 variables together then it is known as Multivariate Analysis. we will work on different plots for Bivariate as well on Multivariate Analysis.
First, let’s explore the plots when both the variable is numerical.
To plot the relationship between two numerical variables scatter plot is a simple plot to do. Let us see the relationship between the total bill and tip provided using a scatter plot.
sns.scatterplot(tips["total_bill"], tips["tip"])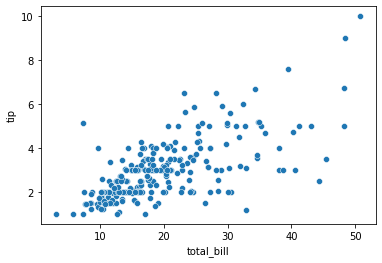
we can also plot 3 variable or 4 variable relationships with scatter plot. suppose we want to find the separate ratio of male and female with total bill and tip provided.
sns.scatterplot(tips["total_bill"], tips["tip"], hue=tips["sex"])
plt.show()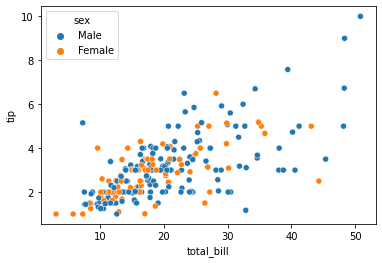
We can also see 4 variable multivariate analyses with scatter plots using style argument. Suppose now along with gender I also want to know whether the customer was a smoker or not so we can do this.
sns.scatterplot(tips["total_bill"], tips["tip"], hue=tips["sex"], style=tips['smoker'])
plt.show()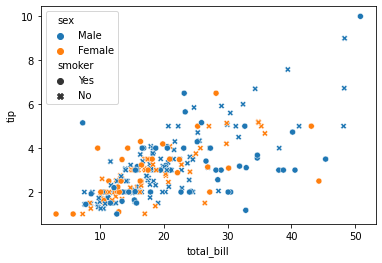
If one variable is numerical and one is categorical then there are various plots that we can use for Bivariate and Multivariate analysis.
Bar plot is a simple plot which we can use to plot categorical variable on the x-axis and numerical variable on y-axis and explore the relationship between both variables. The blacktip on top of each bar shows the confidence Interval. let us explore P-Class with age.
sns.barplot(data['Pclass'], data['Age'])
plt.show()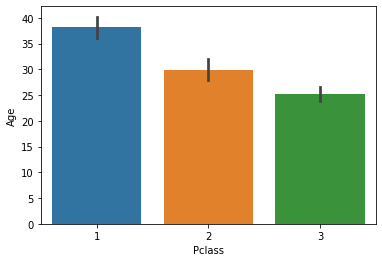
Hue’s argument is very useful which helps to analyze more than 2 variables. Now along with the above relationship we want to see with gender.
sns.barplot(data['Pclass'], data['Fare'], hue = data["Sex"])
plt.show()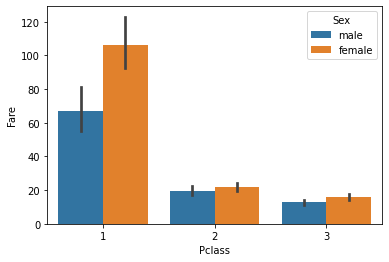
We have already study about boxplots in the Univariate analysis above. we can draw a separate boxplot for both the variable. let us explore gender with age using a boxplot.
sns.boxplot(data['Sex'], data["Age"])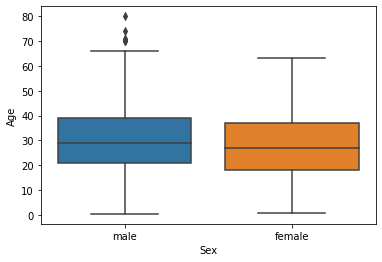
Along with age and gender let’s see who has survived and who has not.
sns.boxplot(data['Sex'], data["Age"], data["Survived"])
plt.show()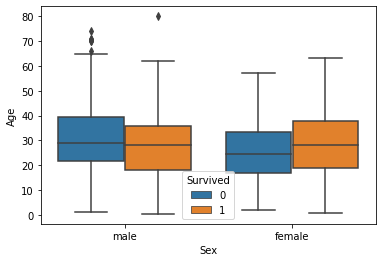
Distplot explains the PDF function using kernel density estimation. Distplot does not have a hue parameter but we can create it. suppose we want to see the probability of people with an age range that of survival probability and find out whose survival probability is high to the age range of death ratio.
sns.distplot(data[data['Survived'] == 0]['Age'], hist=False, color="blue")
sns.distplot(data[data['Survived'] == 1]['Age'], hist=False, color="orange")
plt.show()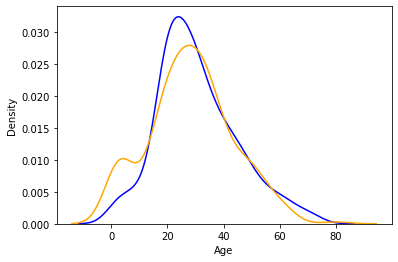
As we can see the graph is really very interesting. the blue one shows the probability of dying and the orange plot shows the survival probability. If we observe it we can see that children’s survival probability is higher than death and which is the opposite in the case of aged peoples. This small analysis tells sometimes some big things about data and It helps while preparing data stories.
Now we will work on categorical and categorical columns.
If you have ever used a crosstab function of pandas then Heatmap is a similar visual representation of that only. It basically shows that how much presence of one category concerning another category is present in the dataset. let me show first with crosstab and then with heatmap.
pd.crosstab(data['Pclass'], data['Survived'])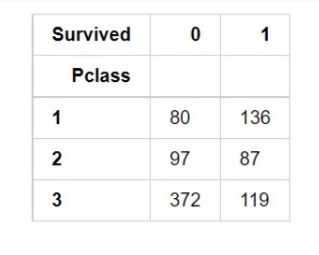
Now with heatmap, we have to find how many people survived and died.
sns.heatmap(pd.crosstab(data['Pclass'], data['Survived']))
we can also use a cluster map to understand the relationship between two categorical variables. A cluster map basically plots a dendrogram that shows the categories of similar behavior together.
sns.clustermap(pd.crosstab(data['Parch'], data['Survived']))
plt.show()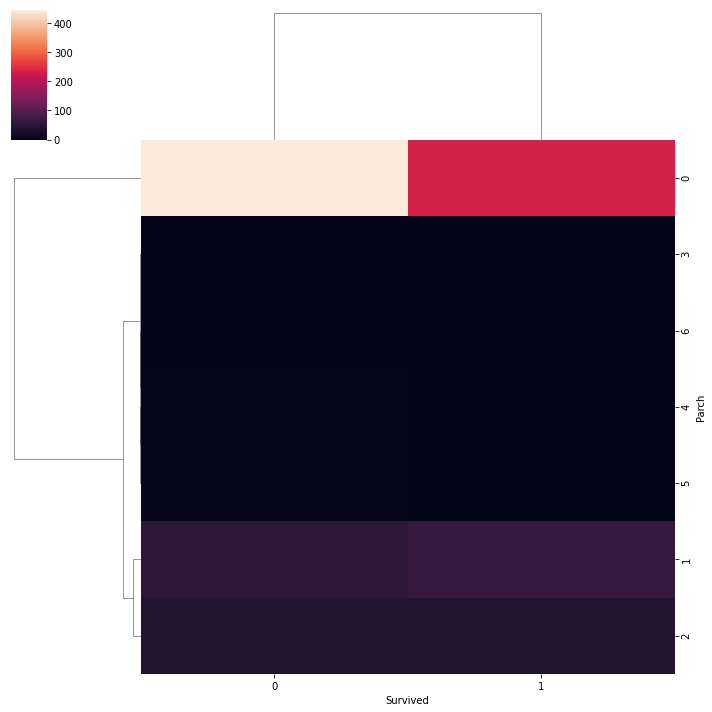
If you know about clustering algorithms mainly about DBSCAN, then you should know about dendrogram. So, these are all the plots that are mostly used while doing exploratory analysis. There are some more plots that you can draw like violent plot, line plot, a joint plot which are not mostly used.
The complete Notebook for more practice on EDA and data visualization is available in my kaggle Notebooks, access it from here.
EDA is only a key to understand and represent your data in a better way which in result helps you to build a powerful and more generalized model. Data visualization is easy to perform EDA which makes it easy to make others understand our analysis.
I hope that it was easy to catch up with all the plots we have drawn. If you have any doubt, please mention them in the comment section below. I will be happy to help you out.
Raghav Agrawal
I am pursuing my bachelor’s in computer science. I am very fond of Data science and big data. I love to work with data and learn new technologies. Please feel free to connect with me on Linkedin.
I am a software Engineer with a keen passion towards data science. I love to learn and explore different data-related techniques and technologies. Writing articles provide me with the skill of research and the ability to make others understand what I learned. I aspire to grow as a prominent data architect through my profession and technical content writing as a passion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Thanks for sharing the details of this course