This week, the AI world has been buzzing with excitement as major players like OpenAI, Mistral AI, NVIDIA, DeepSeek, and Hugging Face unveiled their latest models and innovations. These new releases promise to make AI more powerful, affordable, and accessible. With advancements in training techniques, these developments are set to transform various industries, showcasing the rapid progress and expanding capabilities of AI technology.
OpenAI has launched GPT-4o Mini, a cost-effective and highly capable model designed to replace GPT-3.5 Turbo. Priced at $0.15 per million input tokens and $0.60 per million output tokens, GPT-4o Mini offers improved intelligence and a 128k context window, making it accessible to a broader audience.
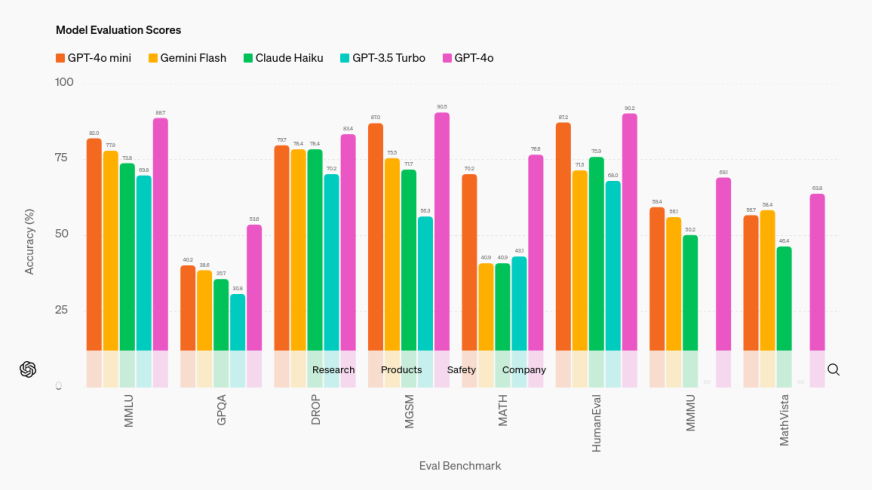
The release has generated excitement due to its potential to democratize access to advanced AI capabilities, though some users have reported limitations in handling large code edits efficiently.
Mistral AI, in collaboration with NVIDIA, unveiled the Mistral NeMo model, a 12B parameter model with a 128k token context window. This model promises state-of-the-art reasoning, world knowledge, and coding accuracy, available under the Apache 2.0 license. Mistral NeMo is designed for broad adoption.
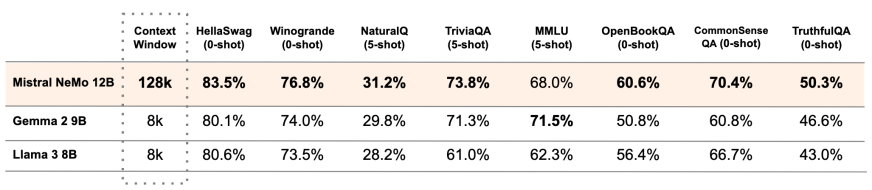
While the model’s capabilities are impressive, some users have raised skepticism about its benchmarking accuracy compared to models like Meta Llama 8B, sparking heated debates among AI engineers.
DeepSeek’s V2 model has significantly reduced inference costs, sparking a competitive pricing war among Chinese AI companies. Known as China’s “AI Pinduoduo,” DeepSeek V2’s cost-cutting innovations could disrupt the global AI landscape.
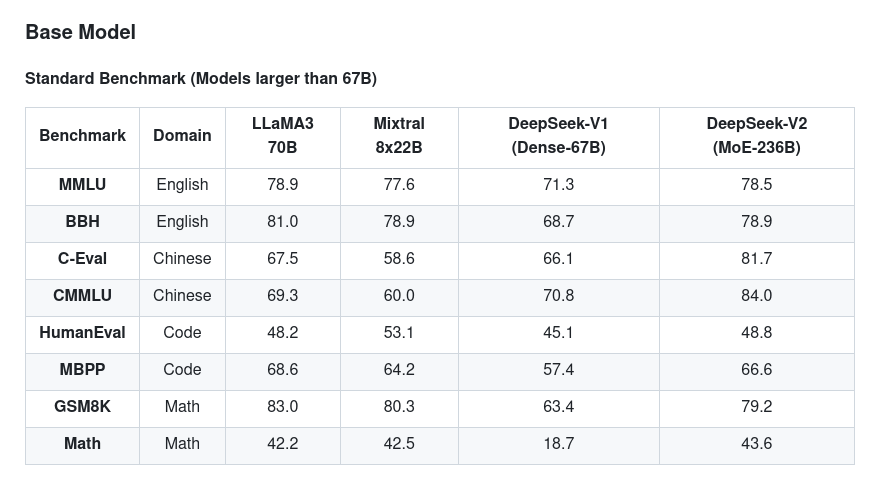
SmolLM, released by Hugging Face, offers a series of small language models in three sizes: 135M, 360M, and 1.7B parameters. These models are trained on Cosmo-Corpus, which comprises Cosmopedia v2 (28B tokens of synthetic educational content), Python-Edu (4B tokens of Python programming examples), and FineWeb-Edu (220B tokens of deduplicated web data). The SmolLM models have demonstrated impressive performance in common sense reasoning and world knowledge benchmarks, positioning them as strong contenders in their size category.
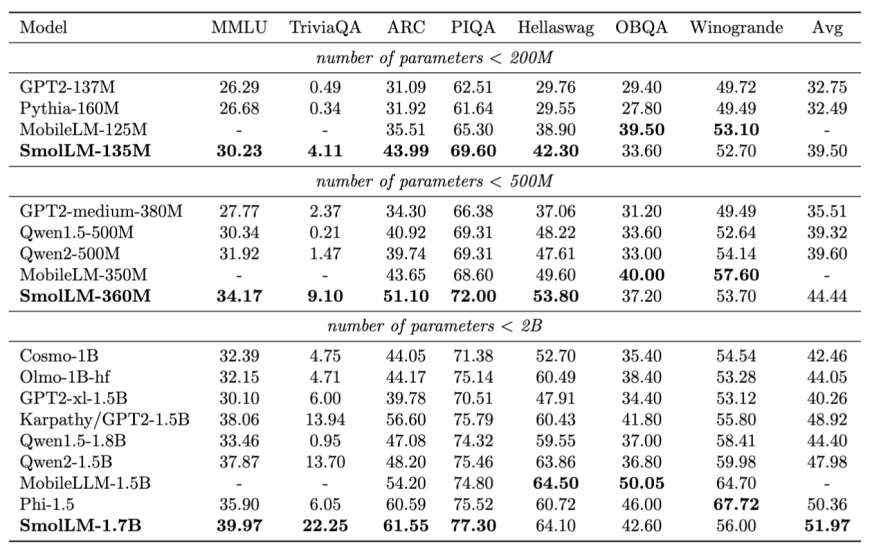
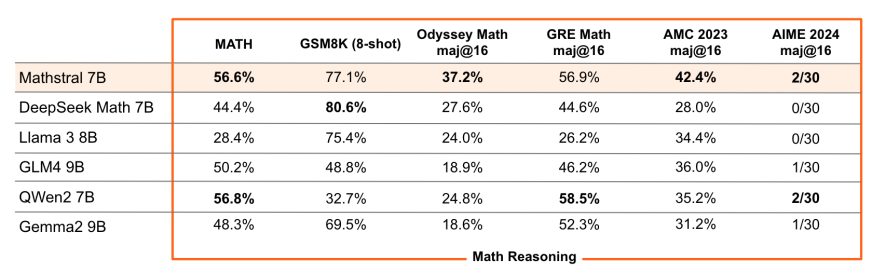
Mistral AI’s Mathstral model, developed in collaboration with Project Numina, is fine-tuned for STEM reasoning, achieving impressive scores on MATH and MMLU benchmarks.Mathstral 7B obtains 56.6% pass@1 on MATH, outperforming Minerva 540B by 20%+. The model exemplifies the growing trend of specialized models optimized for specific domains, potentially reshaping AI applications in scientific and technical fields.
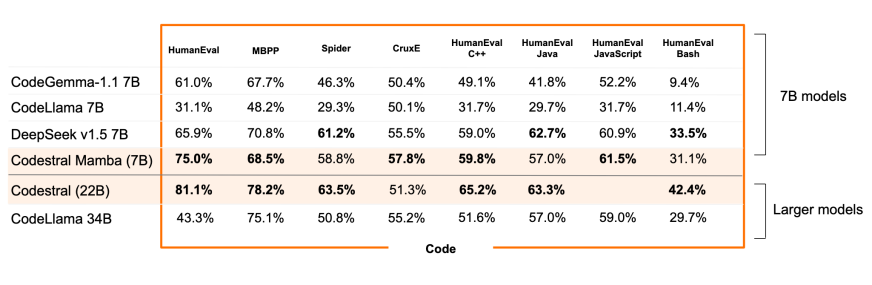
Codestral Mamba, a new model from Mistral AI, offers linear time inference and the ability to handle infinitely long sequences, co-developed by Albert Gu and Tri Dao. The model aims to enhance coding productivity, outperforming existing SOTA transformer-based models while providing rapid responses regardless of input length. The release has generated excitement for its potential impact on LLM architectures, with some noting it’s not yet supported in popular frameworks like llama.cpp.
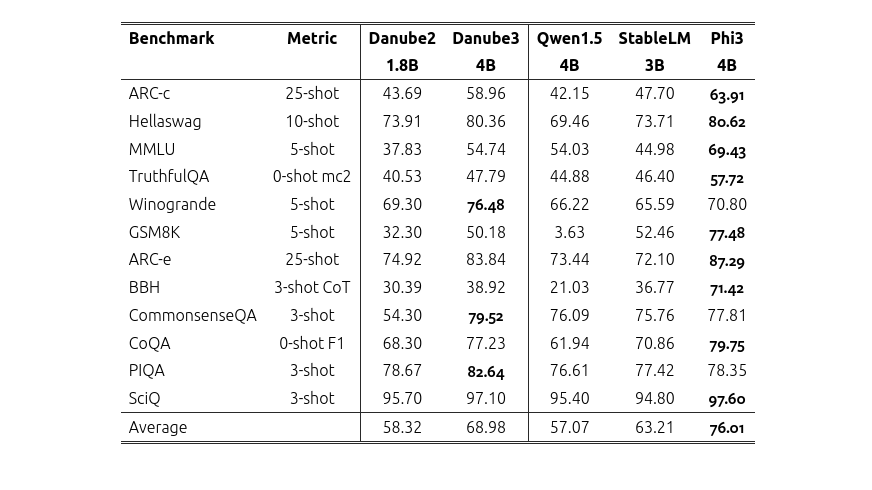
H2O Danube3 introduces a groundbreaking framework for textual feedback differentiation within neural networks, opening new avenues for optimizing compound AI systems beyond conventional methods. The innovative STORM system demonstrates a 25% improvement in article organization by simulating diverse perspectives, enabling LLMs to generate grounded and structured long-form content akin to Wikipedia entries. Researchers herald TextGrad as a paradigm shift in AI, allowing the orchestration of multiple large language models (LLMs) for enhanced performance.
The latest in Microsoft’s Orca series, AgentInstruct, focuses on generative teaching with agentic flows. This technique uses multiple agents to transform raw documents into diverse instructions, resulting in a synthetic dataset that significantly improves model performance.
EfficientQAT, a new quantization algorithm, enables the training of large language models (LLMs) with reduced memory usage and training time. This technique has shown promising results, particularly in training models like Llama-2-70B.
This technique allows fully sparsely-activated LLMs to achieve results comparable to dense baselines with higher efficiency. Q-Sparse represents a significant advancement in LLM training and inference, particularly for resource-constrained environments.
Intuit, the maker of TurboTax, announced a 7% workforce reduction, laying off 1,800 employees as it shifts towards AI and machine learning. This move highlights the growing impact of AI on employment, even in companies reporting significant revenue growth.
The introduction of the OpenGL Shading Language (GLSL) node for ComfyUI allows users to create custom shaders and apply them to images within the ComfyUI workflow. This feature enhances real-time image manipulation using GPU-accelerated operations, opening up new possibilities for advanced visual effects and custom image transformations.
SciCode challenges LLMs to code solutions for scientific problems from advanced papers, including Nobel-winning research. Initial tests showed even advanced models like GPT-4 and Claude 3.5 Sonnet achieving less than 5% accuracy, highlighting the benchmark’s difficulty and the need for more rigorous, domain-specific testing.
The Instruction Following Benchmark (InFoBench) was introduced to evaluate LLMs’ ability to follow instructions. This benchmark has sparked debates on its relevance compared to standard alignment datasets and its potential to highlight valuable LLM qualities beyond high correlations with MMLU.
This week’s AI innovations have the potential to significantly impact various sectors, from making advanced AI capabilities more accessible to driving down costs and improving efficiency. The introduction of models like GPT-4o Mini and Mistral NeMo could democratize AI technology, making it more available to a broader audience, while specialized models like Mathstral and SmolLM can enhance productivity and performance in specific domains.
Additionally, new training techniques and tools such as EfficientQAT and Q-Sparse promise to optimize the development and deployment of AI systems, even in resource-constrained environments. As we continue to witness rapid advancements, these innovations will undoubtedly shape the future of technology and its integration into everyday life.
Follow us on Google News for next week’s update as we continue to track the latest developments in the AI landscape.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,