Diving into the world of AI models, language models and other software that can be applied in real tasks like virtual assistance and content creation are very popular. However, there is still a lot to explore with image-to-text models. Optimal Character Recognition (OCR) is the foundation of building vast encoder-decoder models.
So, when you present images to this model as a sequence, the text decoder generates tokens and displays the characters shown in the image.
Many of these kinds of models have different performance metrics in various specializations. Two popular image-to-text models with great potential are TrOCR and ZhEn Latex OCR; they are distinctively efficient for carrying out different image-to-text tasks.
This article was published as a part of the Data Science Blogathon.
Traditional-based Optimal Character Recognition (TrOCR) is an encoder-decoder model that can read content in an image using an effective sequence mechanism. This model has an image and text transform; the image transformer is the encoder, while the text transfer acts as the decoder.
With OCR models like this, much goes unnoticed when looking into the training of this mode. TrOCR could consist of two categories: the pre-trained models, also known as stage 1 models. These TrOCR models are trained on synthetic data generated on a large scale, which means their data set could include millions of images of printed text lines.
Another important family of the TrOCR model is the fine-tuned models that come after pre-training. These models are usually fine-tuned on the IAM Handwritten text images and SROIE printed receipts dataset. The SROIE consists of samples of thousands of printed texts on small, base, and large scales. So, you have these printed text on scales like this: TrOCR-small-SROIE, TROCR-base-SROIE, TrOCR-SROIE.
OCR models usually use CNN and RNN architectures. CNN was a popular architecture for computer vision and image processing, while RNN was a great system with robust deep learning capabilities. However, in the case of the TrOCR model, the authors (Li et al.) opted for something different.
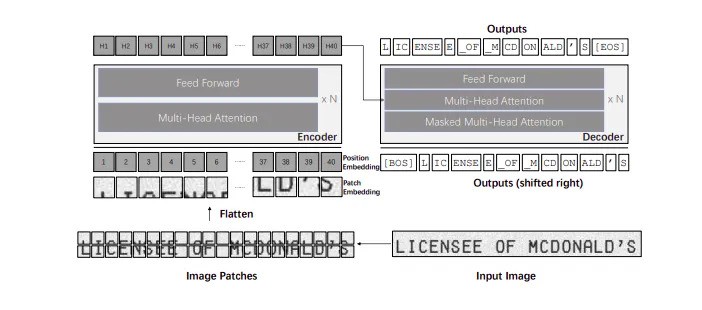
The vision and language transformer model was used to construct the TrOCR architecture. And that brings to light the encoder-decoder mechanism we mentioned earlier. This architecture prints the data sequence in two stages;
The TrOCR model first encodes the image and breaks it into patches that pass through a multi-head attention block. This is followed by a feed-forward block that produces image embeddings. After this, the language transformer model processes these embeddings. The decoder within the transformer generates encoded text outputs.
Finally, these encoded outputs are decoded to extract the text from the image. One important part of this process is that images are resized to fixed-sized patches of 16×16 resolution before they are taken into the text decoder in the transformer model.
Mixtex’s Zhen Latex OCR is another fascinating open-source model with great specialization. It employs an encoder-decoder model to convert images to text. However, it is highly specialized in generating latex code images from mathematical formulas and text. The Zhen Latex OCR can almost accurately recognize complex latex maths formulas and tables. It can also recognize and generate latex table codes.
A fascinating feature of this model is that it can recognize and differentiate between words, text, formulas, and tables while providing accurate recognition results. Zhen Latex OCR is also bilingual, providing recognition in English and Chinese environments.

TrOCR is great but can work efficiently for single-line text images. However, due to its effective pre-training, this model is accurate regarding run time speed compared to other OCR models like Easy OCR. But GPTO remains the most balanced in all aspects.
On the other hand, Zhen Latex OCR works for mathematical formulas and codes. There are software like Anki and MathpixSnip to help with mathematical equations. But the former can be stressful when retyping the latex formula, while the latter is limited with the free plan and has an expensive paid package.
Zhen comes in handy to solve this problem. You can input images on the encoder, and the decoder transformer can convert them to latex. Gemini is another alternative to this model but is only great for solving general maths problems. Zhen Latex’s excellent specialization in converting images to latex makes it stand out. Also, this model is multimodal to recognize and process equations containing words, formulas, tables, and text.
TrOCR is efficient for printing from images with single-line text. For mathematical problems, you have many options, but Zhen can help you with latex recognitions.
We will explore using the TrOCR model, which is fine-tuned with SRIOE datasets. This model is already tailored to deliver accurate results with one-line text images, and we will look at a few steps that make it run.
In summary, this code sets up the environment for OCR using the TrOCR model. It imports the necessary tools for loading images, processing them, and making HTTP requests to fetch images from the internet.
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requestsTo load an image from this database, you have to define the URL of an image from the IAM handwriting database, use the `requests` library to download the image from the specified URL, open the image using the `PIL.Image` module, and convert it to RGB format for consistent color processing. This is the first step of input to get the transformer model to encode the text on the image.
# load image from the IAM database (actually this model is meant to be used on printed text)
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-printed')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-printed')
pixel_values = processor(images=image, return_tensors="pt").pixel_valuesThis step is to initialize the TrOCR model by loading the pre-trained processor. The TrOCRProcessor processes the input image, converting it into a format the model can understand. The processed image is then converted into a tensor format with pixel values, which are necessary for the model to perform OCR on the image. The final output, pixel_values, is the tensor representation of the image, ready to be fed into the model for text recognition.
This step involves the model taking the image input and generating a text output (in pixels). The text generation is done in token IDs, which are taken back into decoded and readable text. The code would look like this:
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]You can view the image below with the ‘image’ prompt. This can help us confirm the output.
image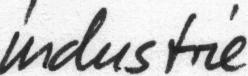
This is a one-line text image; with TrOCR, you can use ‘generated_text.lower()’. You get the text here as ‘INDLUS THE.’
generated_textgenerated_text.lower()Note: the second line brings output in lowercase.

Zhen Latex OCR can also recognize Mathematical formulas and equations. Its architecture is similar to that of TrOCR models, employing a vision encoder-decoder model.
Let us look at a few steps for running this model to recognize images with latex.
from transformers import AutoTokenizer, VisionEncoderDecoderModel, AutoImageProcessor
from PIL import Image
import requests
feature_extractor = AutoImageProcessor.from_pretrained("MixTex/ZhEn-Latex-OCR")
tokenizer = AutoTokenizer.from_pretrained("MixTex/ZhEn-Latex-OCR", max_len=296)
model = VisionEncoderDecoderModel.from_pretrained("MixTex/ZhEn-Latex-OCR")
This code initializes an OCR pipeline using the ZhEn Latex OCR model. It imports the necessary modules and loads a pre-trained image processor (`AutoImageProcessor`) and tokenizer (`AutoTokenizer`) from the Zhen Latex model. These components are configured to handle images and text tokens for LaTeX symbol recognition.
The `VisionEncoderDecoderModel` is also loaded from the same Zhen Latex checkpoint. These components combined would help process images and generate LaTeX-formatted text.
imgen = Image.open(requests.get('https://cdn-uploads.huggingface.co/production/uploads/62dbaade36292040577d2d4f/eOAym7FZDsjic_8ptsC-H.png', stream=True).raw)
#imgzh = Image.open(requests.get('https://cdn-uploads.huggingface.co/production/uploads/62dbaade36292040577d2d4f/m-oVg8dsQbQZ1fDWbwKtO.png', stream=True).raw)
print(tokenizer.decode(model.generate(feature_extractor(imgen, return_tensors="pt").pixel_values)[0]).replace('\\[','\\begin{align*}').replace('\\]','\\end{align*}'))In this step, we load the image using the ‘Pil.Image’ module before processing it. The ‘feature extractor’ function in this code helps to convert it to a tensor format suitable to Zhen Latex.
The model.generate() function then generates LaTeX code from the image, and the resulting token IDs are decoded into a readable format using the tokenizer.decode() method. Finally, the decoded LaTeX code is printed, with specific replacements made to format the output with \begin{align*} and \end{align*} tags.
The output of the image with latex is in the screenshot and code block below:
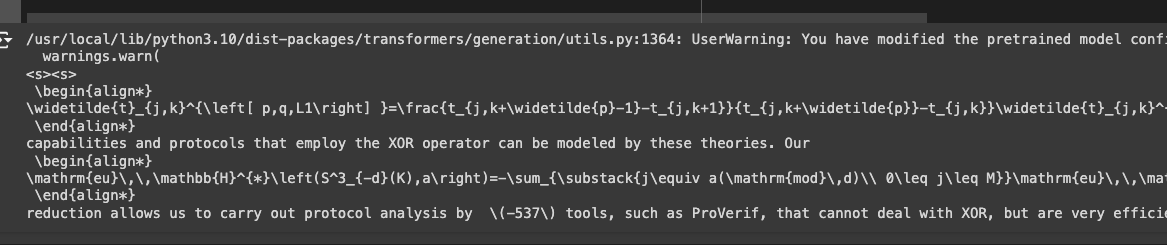
begin{align*}
\widetilde{t}_{j,k}^{\left[ p,q,L1\right] }=\frac{t_{j,k+\widetilde{p}-1}-t_{j,k+1}}{t_{j,k+\widetilde{p}}-t_{j,k}}\widetilde{t}_{j,k}^{\left[ p,q,L1b\right] },
\end{align*}
capabilities and protocols that employ the XOR operator can be modeled by these theories. Our
\begin{align*}
\mathrm{eu}\,\,\mathbb{H}^{*}\left(S^3_{-d}(K),a\right)=-\sum_{\substack{j\equiv a(\mathrm{mod}\,d)\\ 0\leq j\leq M}}\mathrm{eu}\,\,\mathbb{H}^{*}\left(T_j,W\right).
\end{align*}
reduction allows us to carry out protocol analysis by \(-537\) tools, such as ProVerif, that cannot deal with XOR, but are very efficient in the XORfree case. We
If you enter the ‘image’ prompt, you can see the image of the equation with latex.
imgen
Both models have some limitations, which can be improved in future updates. TrOCR cannot effectively recognize curved texts and images. It also has limitations with images of natural scenes such as banners, billboards, and costumes.
This problem concerns the vision and language transformer models. If the vision transformer model has seen curved texts, it could recognize such images. Similarly, the language transformer would need to understand the different tokens within the texts.
On the other hand, Zhen Latex OCR could also use some updates. This model currently supports only formulas in printed fonts and simple tables. An upgrade would help it convert complex tables into latex code and work with handwritten mathematical formulas.
Many use cases and applications of OCR models exist in the modern digital space. The best part is how useful OCR models can be to different industries. Here are just a few applications of this technology in different industries.
OCR models like TrOCR and Zhen Latex efficiently perform image-to-text/latex code tasks. They reduce errors and provide useful applications in different industries. However, it is important to note that these models have strengths and weaknesses, so optimizing each of them for what they do best would be the best way to achieve accuracy.
These models have many talking points as they have unique and specific strengths with their architecture. Here are some of the key takeaways from the use cases of TrOCR and Zhen Latex OCR models:
A: TrOCR specializes in writing text from printed fonts and handwritten images. On the other hand, Zhen Latex OCR helps convert images using mathematical equations and latex code.
A: Use TrOCR when extracting text from images, especially single-line text, as it is optimized for this task. Zhen Latex OCR should be used when dealing with mathematical formulas or LaTeX code.
A. Zhen Latex OCR currently does not support handwritten mathematical equations. However, upgrades being considered would bring improvements, such as multimodal features, bilingual support, and a handwritten database for mathematical equations.
A: OCR models benefit industries like finance for data extraction, healthcare for digitizing patient records, banking for customer transactional records, and government for processing and digitizing documents.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hey there! I'm David Maigari a dynamic professional with a passion for technical writing writing, Web Development, and the AI world. David is an also enthusiast of data science and AI innovations.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,